

For most workloads the Postgres Autovacuum daemon works just fine. You go about your day with 3 workers that wake up once a minute to make sure that everything is nice and tidy. If things are dirty enough (around 10%) then one of the workers gets in gear and cleans things up. Unfortunately, if you have an inverted load from the norm, Autovacuum may not be able to keep up and you will suffer increased fragmentation and bloat.
The norm
The most common workload for Postgres (especially web based apps) includes many reads and some writes. It is usually somewhere around 75-95% reads and 5-25% writes. Assuming an average database, Autovacuum will keep up just fine and with tuning will continue to perform well as a whole even as your TPS increases.
When Autovacuum fails
A couple of weeks ago I was teaching at PGConf US Local: Philly on Postgres Performance and Maintenance. While discussing various nuances of Postgres life with Jim Mlodgenski and Jan Wieck (He’s the guy that created Slony, PL/TCL and TOAST), the issue of Autovacuum not keeping up arose. Under Jan’s tests using BenchmarkSQL he was not able to get Postgres to run under a heavy write/update load for much longer than a week.
DO NOT FREAK OUT

Remember that this problem is obscure, special case, and you likely will not run into it. That does not mean it isn’t good to talk about and see if we can make it better (which is exactly what is happening here, here and here). I expect that some changes (minor) will make it into v10 and of course work will commence for v11. This is one of the great things about the Postgres release cycle; you are not going to have to wait for three years to see improvement. We generally release yearly (give or take) and v10 is set to hit soon.
Prove it!
I was incredulous at Jan’s claims. We have systems that have been running non-stop except for dot release updates for years. How could a system that runs for years without intervention be subject to such an unfortunate limitation? The answer to that question is the workload. As mentioned previously most workloads do not fit into this category. I set out to do some testing because I had not seen anything over at .Org regarding this problem.
The machine
- GCE
- 16vCPU
- 59G Memory
- 10G SSD (/)
- 500G SSD /srv/main/9.6 (PGDATA) : 240MB Sustained with 15k IOPS
- Yes, we really got 240MB sustained performance
Postgres configuration
|
General |
Autovacuum |
|
max_connections: 1000 shared_buffers: 32G work_mem: 32M maintenance_work_mem: 2G effective_io_concurrency: 1 synchronous_commit: off checkpoint_timeout: 1d max_wal_size: 10GB random_page_cost: 1 effective_cache_size: 32GB |
Autovacuum: on Autovacuum_analyze_scale_factor: 0.1 Autovacuum_analyze_threshold: 50 Autovacuum_freeze_max_age: 200000000 Autovacuum_max_workers: 12 Autovacuum_multixact_freeze_max_age: 400000000 Autovacuum_naptime: 10 Autovacuum_vacuum_cost_delay: 0 Autovacuum_vacuum_cost_limit: 5000 Autovacuum_vacuum_scale_factor: 0.1 Autovacuum_vacuum_threshold: 50 Autovacuum_work_mem: -1 Log_autovacuum_min_duration: -1 Max_wal_size: 640 Checkpoint_timeout: 86400 Checkpoint_completion_target: 0.5 |
Benchmark configuration
We used the defaults for weight but ran with 500 warehouses, 128 terminals (connections), and a run time of six hours per test. Here are the results:
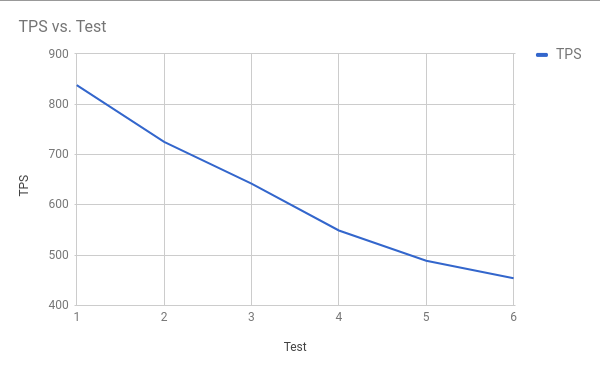
As you can see with each subsequent test the TPS went down significantly and there is a direct correlation with the TPS drop and the size of the database as it grows (illustrated in the next graph):
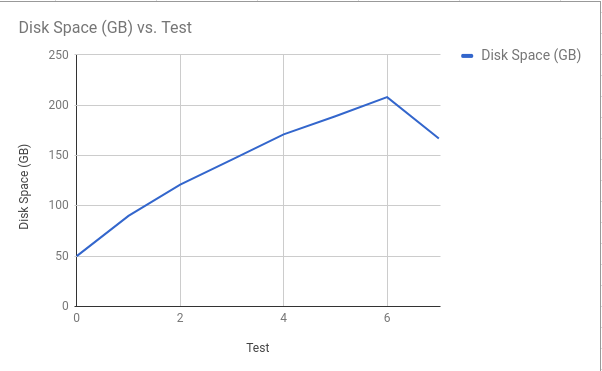
The drop of disk size after test six is due to a vacuum full being performed when the tests were complete. This shows not only the growth of the database but how much of the database was bloat. The next graphs show where the bloat is. The primary culprit is the following table and index:
|
Relation |
Size at test six |
After VACUUM FULL |
|
bmsql_order_line |
148GB |
118GB |
|
bmsql_order_line_pkey |
48GB |
27GB |
Although the bloat on bmsql_order_line isn’t egregious the bloat on the pkey is rather significant. There is another item at play here, fragmentation within the table, but that is going to have to wait for another post.
I was reminded to never assume a result but instead prove the result. I never considered that this could be a problem because our clients generally do not have this type of workload but these workloads are not unheard of. It is TPC-C and places like Amazon or Staples could have workloads like this.
I also learned that GCE really can push 240MB/s on their SSD volumes and it is beautiful. I still remember when we needed 50 spindles to get that level of performance.